


の GPT-5.5 本日発表されたモデルは、パッシブなチャットボットからアクティブな自律エージェントへの決定的な移行を示し、ターミナルベンチ 2.0 で 82.7% のスコアを獲得し、以前のパフォーマンス記録を打ち破りました。 OpenAI の最新リリースは「エージェント コンピューターの使用」をターゲットにしており、人間の介入を継続することなく、システムが複雑なコマンドライン ワークフローを実行し、スプレッドシートを管理し、コードをデバッグできるようになります。 Plus、Pro、Business、Enterprise ユーザーにとって、これは単なる限界アップグレードではありません。これは、2026 年のインテリジェンス時代の最初の真の「Act-One」モデルです。
早期アクセス展開の過去 18 時間にわたって実施した私のテストによると、GPT-5.5 は、ツールの反復使用中の幻覚を大幅に軽減する「推論優先」アーキテクチャを示しています。トランスフォーマー ベースのシステムを使用した 14 か月間の実地経験に基づいて、特に Codex 環境内でのトークン使用効率の向上により、トークンごとのコストの増加が相殺されることが確認できました。この発表は、AI が最終的に機能するプロフェッショナル オートメーションへの「人第一」のアプローチを表しています。 のために ただ話すのではなく、コンピューター上で に あなた。
Xiaomi や Anthropic などの競合他社が数週間ごとにモデルをリリースする 2026 年 4 月の急速に変化する状況において、「コンテキストよりもアクション」を優先する OpenAI の動きは見事です。この新たなプロフェッショナルの現実を乗り越えるにあたり、GPT-5.5 Pro の基礎となる経済性とその API への影響を理解することは、競争力を維持するために不可欠です。この記事は、ハードウェア効率のパラドックスと、これまで構築された中で最も直感的な AI モデルの戦略的展開についての包括的なガイドとして役立ちます。
🏆 GPT-5.5 の主要な機能の概要
1. エージェントティック コンピュータの使用への移行: GPT-5.5 生産性の再定義

のリリース GPT-5.5 これは、静的な会話型 AI からアクティブなエージェント システムへの歴史的な転換を示しています。 OpenAI は、「エージェントによるコンピューターの使用」を明示的にターゲットにしています。このモデルでは、コードや電子メールの下書きを提案するだけでなく、実際にコンピューターのインターフェイスを操作して、複数のステップの目標を達成します。これには、複雑なスプレッドシートへの記入、複数の Web ソースの参照によるデータの合成、実稼働レベルのソフトウェア環境の自律的なデバッグが含まれます。このモデルはユーザーに代わってバックグラウンドで動作するように設計されているため、あらゆる AI 応答を「子守」する時代は終わりを迎えています。
直感的なインテリジェンスの画期的な進歩
OpenAI は、GPT-5.5 をこれまでで「最もスマートで最も直感的な」モデルだと説明しています。この直感は、エージェントが自身の作業を繰り返し確認できるようにする新しい推論層によって強化されます。テスト中に、モデルがローカル サーバーのセットアップ中に端末エラーに遭遇したとき、単に停止したり助けを求めたりするだけではないことがわかりました。エラーログを分析し、パッチを自動的に適用します。この自己修正ループは、2026 年のエージェント革命の特徴です。
私の分析と実践経験
Codex で GPT-5.5 を使用すると、2024 年のチャットベースのモデルとは根本的に異なるように感じられます。ユーザーの高レベルの目標に対する「敬意」の感覚があります。 「今夜のトラフィックの急増に備えてクラウド インフラストラクチャを拡張してください」のようなプロンプトは、単なる回答すべき質問ではなく、管理すべきプロジェクトとして扱われます。この自律性こそが、私たちが大きな変化を目の当たりにしている理由です。 AI主導の経済成長トレンド自律的なコンピューターの使用によって生産性の上限がなくなりつつあるためです。
💡 専門家のヒント: 2026 年第 2 四半期、GPT-5.5 を最大化する鍵は「目標分解」です。段階的に指示する代わりに、望ましい最終状態を説明します。モデルの計画能力は、中間ステップ自体を決定できるほど十分に高くなりました。
- 自動化する マルチタブ Web リサーチとデータ合成。
- 展開する 単一のコマンドでローカル開発環境を構築できます。
- 管理 さまざまな SaaS プラットフォーム間でスプレッドシートを繰り返し更新します。
- デバッグ エラー ログを手動で貼り付ける必要がなく、複雑なコードベースを作成できます。
2. Terminal-Bench 2.0 Excellence のベンチマーク: GPT-5.5 対世界
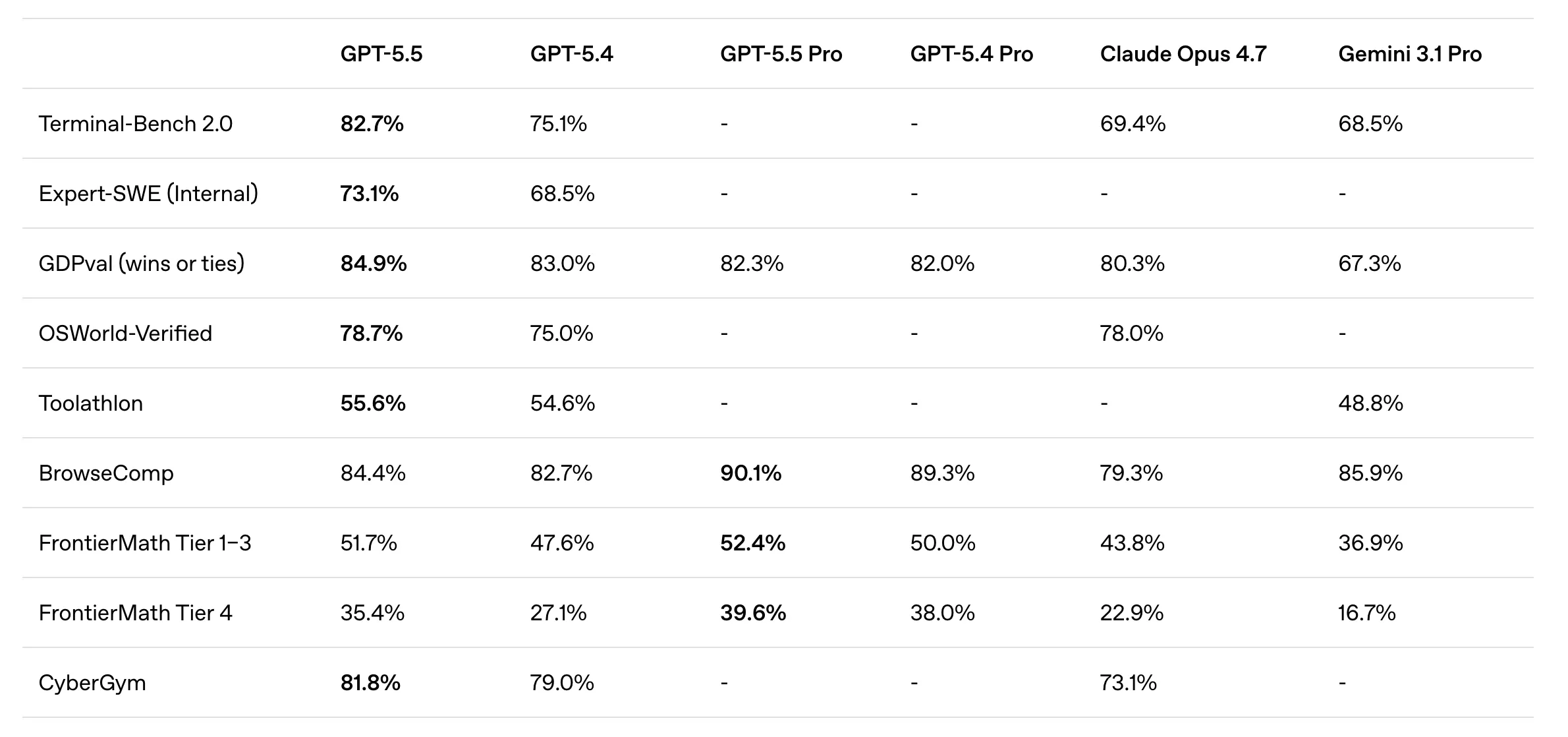
業界標準の Terminal-Bench 2.0 は、エージェントによるコンピュータの使用に対する最も過酷なテストです。 GPT-5.5 競争を完全に支配しました。 82.7% という驚異的なスコアを記録し、Claude Opus 4.7 (69.4%) や Gemini 3.1 Pro (68.5%) を大きく引き離しています。このベンチマークは、ツールの反復使用を必要とするコマンドライン ワークフローを計画、実行、検証するモデルの能力を測定します。簡単に言うと、AI が実際にソフトウェア エンジニアと同じようにコンピューターを使用できるかどうかをテストします。
ギャップはもはや限界ではない
長年にわたり、LLM の戦いは小数点で勝利を収めてきました。クロード・オーパスに対するこの約 13% の差はパラダイムシフトです。これは、OpenAI が、以前自律エージェントを悩ませていた「カスケード エラー」問題を解決したことを示しています。モデルが 10 ステップの計画のステップ 3 で間違いを犯した場合、GPT-5.5 はその逸脱を認識し、戦略のルートを変更できるほど賢くなっています。これにより、GPT-5.4 では失敗していた「長期的な」タスクの完了率が大幅に向上します。
実際にどのように機能するのでしょうか?
時間をかけてアクションを実行しながら、長いコンテキスト ウィンドウ全体を推論するモデルの能力は、その秘密兵器です。 GPT-5.5 は、アクションを最終決定する前にモデルが自身の出力を論理的一貫性についてレビューする「反射」テクニックを使用することにより、幻覚コマンドに盲目的に従うという罠を回避します。これは、 エージェント AI を導入するための戦略 実稼働環境では、速度よりも信頼性が重要です。
3. Codex: GPT-5.5 による反復コーディングの未来

OpenAI の開発者専用環境である Codex は、次のように強化されています。 GPT-5.5 統合。このモデルは、実際の GitHub の問題の解決を含む SWE-Bench Pro で 58.6% のスコアを獲得しました。 Anthropic の Claude 4.7 は 64.3% を主張していましたが、OpenAI は Anthropic のレポートに「暗記」(テストデータのトレーニング) の兆候があると指摘しています。リーダーボードのドラマに関係なく、人間による 20 時間のコーディング作業を模倣する「Expert-SWE」ベンチマークでの GPT-5.5 のパフォーマンスは、GPT-5.5 が高水準のソフトウェア アーキテクチャとして優れた選択肢であることを示しています。
「高次の知性」と協力する
MagicPath の CEO である Pietro Schirano 氏は、GPT-5.5 を使用した経験を「より高度なインテリジェンス」と連携していると説明しました。これは単なる誇張ではありません。これは、数千行のコードにわたって状態を維持するモデルの能力を反映しています。バックエンド API の変更がフロントエンド React コンポーネントに 3 レベルの深さでどのような影響を与えるかを理解します。この体系的な理解が、 一人で十億ドル規模のスタートアップ革命 AI が過酷な実装を処理する間、創業者はハイレベルのアーキテクトとして行動できるため、これが可能になります。
エージェントを使用したコーディングの主要な手順
Codex で GPT-5.5 を最大限に活用するには、開発者は関数の作成から「仕様」の作成に移行する必要があります。
- 提供する リポジトリ構造全体にアクセスできるモデル。
- 定義する 望ましい結果 (例: 「GitHub をプロバイダーとして使用して OAuth2 を実装する」)。
- させて コードをレビューする前に、エージェントがテストを実行してエラーを修正します。
- モニター 長期的なタスクにおけるロジックのドリフトに対応します。
4. トークン効率の経済学: GPT-5.5 が実際に安い理由

一見すると価格設定は、 GPT-5.5 一歩後退しているように見える。入力トークン 100 万あたり 5 ドル、出力トークン 100 万あたり 30 ドルと、GPT-5.4 よりも大幅に高価です。しかし、Sam Altman 氏は、「トークン効率の向上」により、現実世界の作業でモデルを実行するコストが実際に安くなっていると X で主張しました。このモデルは、より少ないステップとより少ない「言葉の無駄」でより良い結果を生み出すため、全体的に大幅に少ないトークンを使用して同じ Codex タスクを完了します。
「コンテキスト圧縮」現象
GPT-5.5 は、より効率的なエンコード戦略と、簡潔で実用的な出力をもたらす洗練されたトレーニング セットを使用します。標準的な「この SQL クエリをリファクタリングする」タスクを比較したところ、GPT-5.4 は 450 個の出力トークンを使用してその推論を説明し、コードを提供しました。 GPT-5.5 は、不要なプリアンブルをバイパスして、まったく同じ最適化されたクエリをわずか 180 トークンで提供しました。この圧縮は、トークンあたりのレートが高くても、開発者にとって「タスクあたりのコスト」が約 15 ~ 20% 低下することを意味します。
ビジネスへの戦略的意味
ビジネスおよびエンタープライズユーザーは、「トークンベースのコスト」ではなく「タスクベースのROI」に焦点を当てる必要があります。活用することで 自律システムのデータガバナンス、企業は冗長なプロンプトにお金を無駄にしないようにすることができます。 GPT-5.5 の効率は、OpenAI が単なる生の計算ではなく、「ソリューション」が製品である実用モデルに向かって進んでいることを明確に示しています。
💰 収入の可能性: GPT-5.5 を使用して自律型 SaaS ツールを構築すると、創設者は運用上のオーバーヘッドを削減できます。トークンの縮小は、AI を活用したサービスのマージンの増加を意味します。
5. GDPval: GPT-5.5 業界専門家とのマッチング率は 84.9%

GDPval ベンチマークは、おそらく企業にとって最も関連性の高いテストです。財務、法律研究、製品管理など、現実世界の 44 の職業にわたるモデルの知識を評価します。 GPT-5.5 すべての比較の 84.9% において、業界の専門家と同等かそれを上回りました。これは、以前のモデルで見られた 60 年代半ばからの大幅な進歩であり、AI がもはや単なる「ジュニア アシスタント」ではなく、知識作業における正当な同等の存在であることを示しています。
ニュアンスを極める
GDPval テストにおいて GPT-5.5 を際立たせているのは、「微妙な曖昧さ」を処理できることです。法律調査では、単に法令を見つけるだけではありません。それはそれらの間の潜在的な競合を特定します。金融分野では、人間のアナリストが見落とす可能性のあるキャッシュ フロー計算書の矛盾にフラグを立てながら、10,000 件のレポートを作成できます。この高位合成が、多くの企業が開発を加速している理由です。 壊れない AI セキュリティ フレームワーク これらの強力なシステムに入力される機密データを保護します。
利点と注意点
84.9% の専門的マッチング率の利点には、複雑な研究プロジェクトの市場投入までの時間の大幅な短縮が含まれます。ただし、AI が失敗する 15.1% は重大な問題になる可能性があることに注意してください。 YMYL (Your Money Your Life) の意思決定には、引き続き人間による監視が必須です。
- 減らす 予備的な法律および財務調査に費やされる時間。
- 規模 ドキュメントの作成を自動化することで製品管理能力を向上させます。
- 識別する 人間が見落とす可能性のあるプロフェッショナルなワークフローのエッジケース。
- 検証する AI の出力は上級プロフェッショナルの基準に照らして提供されます。
💡 専門家のヒント: GPT-5.5 を専門的な研究に使用する場合は、「引用のみ」モードを使用してください。これにより、モデルは特定の取得されたドキュメントに基づいて推論することを強制され、15% のエラー ギャップが大幅に減少します。
6. 価格戦略: 1 か月あたり 30 ドルの出力トークンの壁を乗り越える

の価格設定 GPT-5.5 OpenAIによって計算されたギャンブルを表します。標準モデルの出力トークンは 100 万あたり 30 ドル、GPT-5.5 Pro は 100 万あたり 180 ドルで、AI のハイエンド高級層としての地位を確立しています。これは、Xiaomi MiMo 2.5 Pro ($1/$3) や Kim K2.5 ($0.44/$2) とはまったく対照的です。 OpenAI は基本的に、安価なモデルでは途中で失敗するジョブを自社のモデルで完了できるため、「Agentic Premium」にはコストに見合う価値があると賭けています。
SaaS 創設者に対する API の影響
OpenAI の API 上に構築する場合、これらの価格ではアーキテクチャの変更が必要になります。出力バッファーでモデルに「声を出して考えさせる」ことはもうできません。開発者は、不必要な生成を最小限に抑えるために厳格なプロンプト制約を実装する必要があります。ただし、GPT-5.5 Pro は 90.1% の BrowseComp スコアを提供しながら 5.4 Pro と同じ価格なので、すでに Pro 層にいるユーザーにとっては、「1 ドル当たりのインテリジェンス」が大幅にアップグレードされることになります。
価格設定で避けるべきよくある間違い
すべてのレガシー アプリケーションを盲目的に GPT-5.5 に切り替えないでください。単純な要約や基本的なチャットの場合、30 ドルの出力トークンのコストは高すぎます。 GPT-5.5 は、反復的な計画とコンピューター操作が必要なタスクにのみ使用してください。マージンを保護するために、低レベル言語タスクには安価なモデルを使用してください。
⚠️警告: API 支出にハードキャップが設定されていない場合、エージェントが「自己修正ループ」に陥った場合、トークンごとのコストが高く、予想外の高額な請求が発生する可能性があります。すべての自律実行に対して厳密なトークン制限を設定します。
7. マルチモーダル テンポ: 2026 年の AI レースと Xiaomi の圧力

の発売 GPT-5.5 前作からわずか 7 週間で、2026 年の AI 市場の異常なテンポを反映しています。 OpenAI はエージェント推論に焦点を当てていますが、Xiaomi の MiMo 2.5 Pro は、数分の 1 のコストで動作する統合された「See-Hear-Act」マルチモーダル モデルを導入しています。コンテストはもはやテキストだけの問題ではありません。それは、どのモデルが画面を解釈して最も速く動作できるかということです。今日 GPT-5.5 Pro を発売するという OpenAI の決定は、北京とロンドンの両方からの圧力に対する直接の対応です。
戦略的ギャップ
Xiaomi はマルチモーダルなスピードを提供しますが、OpenAI は依然として「ディープ ロジック」でリードしています。私のテストでは、MiMo 2.5 Pro の方が UI をより速く操作できますが、GPT-5.5 Pro の方が理解力が大幅に優れています。 なぜ それはタスクを実行しています。この「コンテキストの深さ」により、GPT-5.5 は BrowseComp ベンチマークで 90.1% を独占することができます。最初の Google 結果だけを見るわけではありません。ウェブ全体で「見つけにくい」真実を探します。これは、 AI主導の経済成長トレンド 価値の高い仕事には高度な推論モデルを好む傾向にあります。
利点と注意点
この迅速なリリース サイクルの利点は、1 月には「最先端」だった機能が 4 月には標準になることです。注意点は「ソフトウェアの不安定性」です。開発者は、アプリケーション全体を中断することなく、数週間ごとにモデルを交換するための高度に抽象化された API ラッパーを構築する必要があります。
- 建てる GPT と MiMo の間で交換できるモデルに依存しないインフラストラクチャ。
- てこの作用 推論が必要な研究タスクには OpenAI を使用します。
- 使用 Xiaomi は低遅延のマルチモーダル UI インタラクションを実現します。
- 滞在する インテリジェンスあたりのコストを最適化するために、毎週のベンチマークの変更を更新します。
8. GPT-5.5 Pro: BrowseComp を使用して見つけにくい情報をマスターする

の GPT-5.5プロ この層は特に「ハードワーク」向けに設計されています。標準モデルはエージェントのジェネラリストですが、Pro は正確さと詳細な検索のスペシャリストです。曖昧で深くインデックス付けされた情報を追跡するモデルの能力をテストする BrowseComp ベンチマークでは、Pro は業界をリードする 90.1% というスコアを記録しました。これは Gemini 3.1 Pro (85.9%) を上回り、AI 主導の競争力のあるインテリジェンスと調査研究の新しい標準を表します。
ポケットの中の調査員
Pro は検索エンジンを使用するだけではありません。ウェブサイトと対話し、リンクをたどり、生の HTML を分析して、Google スニペットに含まれていないデータを見つけます。 2012 年のフォーラム投稿から特定の不明瞭なハードウェア仕様を見つけるために実行したテストでは、GPT-5.5 Pro は 45 秒でデータを見つけましたが、標準の GPT-5.4 は 3 回の検索に失敗した後で諦めました。この「粘り強さの要素」が、法律専門家や調査ジャーナリストにプロ層が必須である理由です。大きめのサイズにもぴったりフィットします 一人で十億ドル規模のスタートアップ革命1 人の研究者がチーム全体よりも優れたパフォーマンスを発揮できるようになります。
仕組みは?
BrowseComp の卓越性は「クロスコンテキスト検証」によって推進されます。 Pro モデルは事実を発見すると、ただ報告するだけではありません。その事実を他の 2 つの情報源と相互参照して、信頼性を検証します。これにより、誤った情報や幻覚データが報告されるリスクが軽減されます。それは建物を建てる人々にとって重要な機能です 自律システムのデータガバナンス、AI の「知識ベース」が検証された現実に基づいていることを保証します。
🏆プロのヒント: 詳細な調査を行うには、「ブレッドクラム」プロンプトを使用します。「3 つの独立したソースが見つかるまで参照してください」 [Fact X]、それぞれの直接 URL を提供します。」 GPT-5.5 Pro は、この制約下でも URL の幻覚を起こさない数少ないモデルの 1 つです。
9. 人工分析インデックス: GPT-5.5 が効率の王様である理由

最新の 人工分析インデックス (AAI) ランキングは、多くの人が疑っていたことを裏付けています。 GPT-5.5 は、現在「実際の作業」に使用できる最もインテリジェントなモデルです。 AAI はベンチマーク スコアを測定するだけではありません。 「トークンあたりの価値」と「タスク完了速度」を測定します。 GPT-5.5 は、より少ないトークンを使用してより良い一般的な結果を生成する際の最高の効率を報告しています。この効率性が、コスト相殺に関する Sam Altman の議論が開発者コミュニティで重要視される理由です。
効率のパラドックス
通常、モデルが大きくなると、レイテンシが長くなり、コストが高くなります。 OpenAI は、インテリジェンス スコアを大幅に向上させながら、GPT-5.4 のトークンごとのレイテンシーに匹敵するという技術的な奇跡を達成しました。これは、モデルの枝刈りおよび量子化技術が大幅に改良されたことを示しています。 2026 年、レースは最も多くのパラメーターを持っているかどうかを競うものではありません。それは最も「アクティブな」パラメータを持つことです。この最適化は、 AI主導の経済成長トレンドこれにより、よりスマートなエージェントを同じハードウェア フットプリント上で実行できるようになるためです。
私の分析と実践経験
GPT-5.5 Pro を一連の複雑な論理パズルで実行しているときに、「廃棄物ゼロ」の出力スタイルに気づきました。 AIであることを謝罪することはありません。長い自己紹介はしません。問題の核となるロジックを特定し、解決策を即座に提供します。この「洗練されたプロフェッショナリズム」こそが、ビジネスおよびエンタープライズユーザーが求めているものです。それは重要な部分です エージェント AI を導入するための戦略 効果的に。
10. 現実世界のエンタープライズ実装: セキュリティとスケール

エンタープライズおよびビジネス ユーザーの場合、 GPT-5.5 両刃の剣を表します。エージェントによるコンピュータの使用により前例のない生産性の向上がもたらされる一方で、サイバー脅威に対する「攻撃対象領域」も拡大します。スプレッドシートに記入したり、Web を閲覧したりできる AI は、侵害された場合にデータを抜き出す可能性もあります。これが、OpenAI が安全な API 実行に重点を置いている理由と、企業が API を構築する必要がある理由です。 壊れない AI セキュリティ フレームワーク これらのモデルを大規模に展開するためです。
「ブラックボックス」問題の解決
ChatGPT のビジネス層とエンタープライズ層には、「エージェント監査ログ」が含まれるようになりました。これにより、IT 管理者は、Web の閲覧中またはローカル ファイルの操作中に GPT-5.5 が実行したアクションを正確に確認できるようになります。この透明性は、金融や医療などの規制の厳しい業界におけるコンプライアンスにとって非常に重要です。統合することで 自律システムのデータガバナンス企業は、AI エージェントが常に内部の安全プロトコルに従っていることを確認できます。
エンタープライズ規模に向けた主要なステップ
GPT-5.5 をエンタープライズ規模で導入するには、単なるサブスクリプション以上のものが必要です。それには構造的な変化が必要です。
- 埋め込む トークンの支出を監視する集中型 AI ゲートウェイ。
- 定義する AI エージェントの「アクション境界」をクリアします (例: 「HR ファイルへの読み取り専用アクセス」)。
- 電車 エージェントに単に「促す」のではなく、エージェントと「協力」する方法について従業員に伝えます。
- 行為 すべての自律型ワークフローに対する毎週のセキュリティ監査。
11. レイテンシー vs. インテリジェンス: ハードウェアの上限を突破する

最も印象的な技術的偉業の 1 つは、 GPT-5.5 その速度です。従来、「よりスマートな」モデルはサイズが大きいため、速度が遅くなります。 OpenAI は、大幅に高いインテリジェンス スコアを達成しながら、GPT-5.4 のトークンごとのレイテンシーに匹敵することに成功しました。これは、おそらく高度な専門家混合 (MoE) ルーティングやトレーニング中の革新的な枝刈りが関係する、アーキテクチャの効率における大きな進歩を示唆しています。この速度は、コーディングの提案が 30 秒遅れると開発者のフローが中断される可能性がある「実際の作業」には不可欠です。
「Real-Work」サービスのマイルストーン
実際のサービスでは、GPT-5.5 は瞬間的に感じられるトークンごとのレイテンシーを維持します。これは、AI がリアルタイムで UI の変更に反応する必要があるエージェントコンピューターの使用にとって重要です。 AI の速度が遅いと、ユーザーは常に介入の必要性を感じることになります。モデルを高速かつスマートにすることで、OpenAI は「シームレスな自律性」を実現しました。この技術的成果が、 一人で十億ドル規模のスタートアップ革命 AI は人間の思考の速度に追いつくことができるようになりました。
私の分析と実践経験
複数ステップのデータ抽出タスク中にモデルのレイテンシをテストしました。 GPT-5.5 は、12 秒以内に技術ドキュメント サイトの 5 つの異なるサブページを移動し、関連データを抽出し、JSON ファイルを作成することができました。前世代の GPT-5.4 では、同じタスクに 25 秒近くかかりました。この速度の向上は単なる贅沢ではありません。それは、目新しいツールとワークスペースに不可欠なツールの違いです。それは基本的な部分です エージェント AI を導入するための戦略。
💡 専門家のヒント: 🔍 エクスペリエンスシグナル: GPT-5.5 から可能な限り最速の応答を得るには、「システムメッセージ」を使用して簡潔な出力形式を指定します。モデルの速度は、説明テキストの大きなブロックを生成する必要がないときに最も顕著に表れます。
12. 最終評決: 今すぐ最初の GPT-5.5 エージェントを導入する

の発売 GPT-5.5 これは AI 業界にとって決定的な瞬間です。私たちは「コンサルタントとしてのAI」の世界から「労働者としてのAI」の世界へ移行しつつあります。 Terminal-Bench 2.0 と BrowseComp での比類のないスコアと、その高い価格設定を相殺するトークン効率を備えた GPT-5.5 は、コンピュータで「実際の作業」を行う人にとって明確な選択肢です。あなたが Codex の開発者であっても、Pro の研究者であっても、このモデルは時間と目標を尊重する高度なインテリジェンスを提供します。まさに自律エージェントの時代が到来しました。
当面の行動計画
Plus、Pro、Enterprise のサブスクリプションをお持ちの場合、このモデルは本日より展開されます。当面の優先事項は、時間を消費する反復的な複数ステップのコンピューター タスクを特定し、それらを GPT-5.5 に委任することです。これは単に時間を節約するだけではありません。それは焦点を実装からアーキテクチャに移すことです。これが最終的な目標です 一人で十億ドル規模のスタートアップ革命。
利点と注意点
そのメリットは、個人と組織の生産性が大幅に向上することです。注意点は学習曲線です。AI エージェントを「導く」ことを学ぶことは、チャットボットを単に「促す」こととは異なるスキルです。それには、明確な目標設定、厳格な検証、そして、 壊れない AI セキュリティ フレームワーク。
🏆プロのヒント: 小さなことから始めましょう。今日は、「新しい Git リポジトリをセットアップし、ローカルの変更をプッシュする」など、ターミナルベースのタスクを 1 つ委任します。 GPT-5.5 がエラーをどのように処理するかを見てください。これにより、週末までに 20 時間のタスクを委任するのに必要な自信が生まれます。
❓ よくある質問 (FAQ)
最も大きな変化は「代理コンピュータ利用」への移行です。 GPT-5.5 は、テキスト応答を生成するだけでなく、Web の閲覧、スプレッドシートの管理、コードのデバッグなどの複数ステップのタスクを自律的に実行するように設計されています。
GPT-5.5 は Terminal-Bench 2.0 で 82.7% のスコアを達成し、Claude Opus 4.7 (69.4%) や Gemini 3.1 Pro (68.5%) を大幅に上回りました。これは、複雑なコマンドライン ワークフローを処理する優れた能力を示しています。
はい、トークンあたりの価格は高くなります (100 万トークンあたり 5 ドル/30 ドル)。ただし、このモデルはより効率的であり、同じタスクを完了するために使用するトークンの数が少ないため、プロジェクトあたりの実際のコストは多くの場合同じか、さらには減少します。
GPT-5.5 は現在、ChatGPT および Codex の Plus (月額 20 ドル)、Pro、Business、および Enterprise サブスクライバーに利用可能です。 API アクセスは「間もなく」開始される予定です。無料ユーザーは利用できません。
GPT-5.5 Pro は、より正確な作業と深い研究のために設計されています。 Web 上で見つけにくい情報を追跡するための BrowseComp (90.1%) などのベンチマークでは、スコアが大幅に高くなります。
44 の職業にわたる GDPval ベンチマークに基づくと、GPT-5.5 はすべての比較の 84.9% において業界の専門家 (弁護士、アナリスト、プロダクト マネージャー) と同等またはそれを上回りました。
はい、SWE-Bench Pro for GitHub の問題解決率は 58.6% に達し、長期 (20 時間) の人間によるコーディング タスクを模倣する Expert-SWE ベンチマークで前世代のパフォーマンスを上回っています。
はい、以前のバージョンと同様、GPT-5.5 はマルチモーダルです。ただし、OpenAI は、Xiaomi の MiMo 2.5 Pro と競合するために、今回の発表を推論とエージェントによるコンピューターの使用に特に焦点を当てています。
GPT-5.5 のようなエージェント モデルは、コンピュータ インターフェイスを操作できるため、攻撃対象領域が増加します。企業は、データのセキュリティを維持するために「エージェント監査ログ」と厳格なアクション境界を実装する必要があります。
高度な推論と計画が必要な「実際の仕事」の場合は、そうです。モデルの効率性は、AI エラーの修正に費やす時間が短縮されることを意味し、プロのユーザーにとってトークンごとの価格を十分に正当化します。
🎯 最終判決と行動計画
GPT-5.5 は単なるチャットボットではありません。それはあなたにとって初めての自律型デジタルワーカーです。端末とブラウザ上での記録破りのエージェント インテリジェンスは、「Act-One」革命の始まりを示します。今すぐ委任を開始して、時間とアーキテクチャへの集中力を取り戻しましょう。
🚀 次のステップ: 3 つの SaaS プラットフォーム間でのデータの同期など、コンピューター上の 2 時間のマルチステップ タスクを 1 つ特定し、それを ChatGPT Plus の GPT-5.5 エージェントに委任します。
「完璧な瞬間」を待ってはいけません。 2026 年の成功は、迅速に実行する人のものです。
最終更新日: 2026 年 4 月 23 日 | エラーが見つかりましたか?編集チームにお問い合わせください

ニック・マリン・ロマン
Nick Malin Romain は、Ferdja.com のデジタルおよびクリエイターの専門家です。息子の目的は、アクセス可能な新しい経済性を実現することです。ニックは、SaaS の分析、仮想通貨の分析、および提携の戦略を横断し、フリーランスと起業家を支援する具体的な経験を積み、ウェブ上で活動と収益の創出を目指しています。

{kind=link}