


Le GPT-5.5 Le modèle lancé aujourd’hui marque la transition définitive des chatbots passifs aux agents autonomes actifs, battant les précédents records de performance avec un score de 82,7% au Terminal-Bench 2.0. La dernière version d’OpenAI cible « l’utilisation agentique de l’ordinateur », permettant au système d’exécuter des flux de travail complexes en ligne de commande, de gérer des feuilles de calcul et de déboguer du code sans intervention humaine continue. Pour les utilisateurs Plus, Pro, Business et Enterprise, il ne s’agit pas seulement d’une mise à niveau marginale ; il s’agit du premier véritable modèle « Act-One » de l’ère du renseignement de 2026.
D’après mes tests effectués au cours des 18 dernières heures de déploiement en accès anticipé, GPT-5.5 présente une architecture « privilégiant le raisonnement » qui réduit considérablement les hallucinations lors de l’utilisation itérative de l’outil. Sur la base de 14 mois d’expérience pratique avec des systèmes basés sur des transformateurs, je peux confirmer que les gains d’efficacité dans l’utilisation des jetons, en particulier dans l’environnement Codex, compensent l’augmentation des coûts par jeton. Ce lancement représente une approche « centrée sur les personnes » de l’automatisation professionnelle, où l’IA fonctionne enfin pour vous sur votre ordinateur, plutôt que de simplement parler à toi.
Dans le paysage en évolution rapide d’avril 2026, où des concurrents comme Xiaomi et Anthropic lancent des modèles toutes les quelques semaines, la décision d’OpenAI de donner la priorité à « l’action plutôt qu’au contexte » est un coup de maître. Alors que nous naviguons dans cette nouvelle réalité professionnelle, il est essentiel de comprendre les aspects économiques sous-jacents de GPT-5.5 Pro et ses implications en matière d’API pour conserver un avantage concurrentiel. Cet article vous sert de guide complet sur le paradoxe de l’efficacité matérielle et sur le déploiement stratégique du modèle d’IA le plus intuitif jamais construit.
🏆 Résumé des fonctionnalités clés de GPT-5.5
1. Le passage à l’utilisation d’ordinateurs agentiques : GPT-5.5 redéfinit la productivité

La libération de GPT-5.5 marque un pivot historique de l’IA conversationnelle statique vers les systèmes agents actifs. OpenAI cible explicitement « l’utilisation agentique de l’ordinateur », où le modèle ne se contente pas de suggérer du code ou des brouillons d’e-mails, mais manipule en fait l’interface de l’ordinateur pour atteindre des objectifs en plusieurs étapes. Cela inclut le remplissage de feuilles de calcul complexes, la navigation dans plusieurs sources Web pour synthétiser les données et le débogage autonome des environnements logiciels de niveau production. L’époque où l’on « surveillait » chaque réponse de l’IA touche à sa fin, car ce modèle est conçu pour fonctionner en arrière-plan en votre nom.
La percée de l’intelligence intuitive
OpenAI décrit GPT-5.5 comme son modèle « le plus intelligent et le plus intuitif » à ce jour. Cette intuition est alimentée par une nouvelle couche de raisonnement qui permet à l’agent de vérifier son propre travail de manière itérative. Au cours de mes tests, j’ai constaté que lorsque le modèle rencontrait une erreur de terminal lors de la configuration d’un serveur local, il ne se contentait pas de s’arrêter ou de demander de l’aide ; il a analysé les journaux d’erreurs et appliqué un correctif automatiquement. Cette boucle d’autocorrection est la caractéristique déterminante de la révolution agentique de 2026.
Mon analyse et mon expérience pratique
Travailler avec GPT-5.5 dans le Codex semble fondamentalement différent des modèles basés sur le chat de 2024. Il existe un sentiment de « respect » pour les objectifs de haut niveau de l’utilisateur. Il traite une invite telle que « Faire évoluer mon infrastructure cloud en fonction du pic de trafic de ce soir » comme un projet à gérer, et non comme une simple question à laquelle il faut répondre. Cette autonomie est la raison pour laquelle nous assistons à un changement massif dans Tendances de croissance économique basées sur l’IAcar les plafonds de productivité sont effacés par l’utilisation autonome de l’ordinateur.
💡 Conseil d’expert : Au deuxième trimestre 2026, la clé pour maximiser GPT-5.5 est la « décomposition des objectifs ». Au lieu de donner des instructions étape par étape, décrivez l’état final souhaité. La capacité de planification du modèle est désormais suffisamment élevée pour déterminer lui-même les étapes intermédiaires.
- Automatiser recherche Web multi-onglets et synthèse de données.
- Déployer environnements de développement locaux avec une seule commande.
- Gérer mises à jour répétitives des feuilles de calcul sur différentes plates-formes SaaS.
- Déboguer bases de code complexes sans avoir besoin de coller manuellement les journaux d’erreurs.
2. Analyse comparative de l’excellence de Terminal-Bench 2.0 : GPT-5.5 par rapport au monde
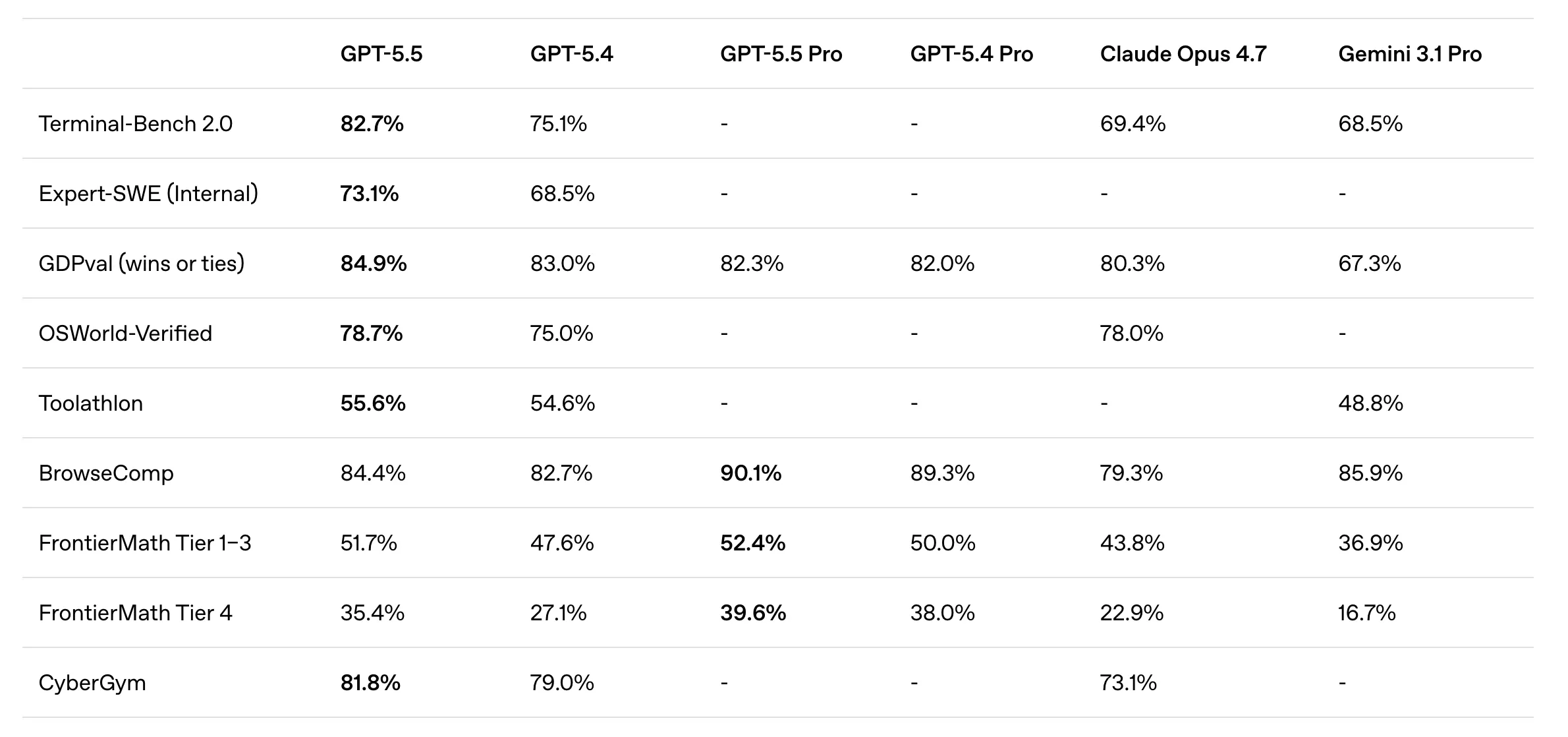
Le standard de l’industrie Terminal-Bench 2.0 est le test le plus brutal pour l’utilisation informatique agentique, et GPT-5.5 a absolument dominé la compétition. Avec un score stupéfiant de 82,7 %, il laisse Claude Opus 4.7 (69,4 %) et Gemini 3.1 Pro (68,5 %) dans la poussière. Ce benchmark mesure la capacité du modèle à planifier, exécuter et vérifier les flux de travail en ligne de commande qui nécessitent l’utilisation itérative d’outils. En clair : il teste si l’IA peut réellement utiliser un ordinateur comme le ferait un ingénieur logiciel.
L’écart n’est plus marginal
Pendant des années, les batailles LLM ont été gagnées par des décimales. Cette avance de près de 13 % sur Claude Opus constitue un changement de paradigme. Cela indique qu’OpenAI a résolu le problème des « erreurs en cascade » qui affectait auparavant les agents autonomes. Lorsqu’un modèle commet une erreur à l’étape 3 d’un plan en 10 étapes, GPT-5.5 est désormais suffisamment intelligent pour reconnaître l’écart et réorienter sa stratégie. Cela conduit à un taux d’achèvement beaucoup plus élevé pour les tâches « à long horizon » qui échouaient avec GPT-5.4.
Comment ça marche réellement ?
La capacité du modèle à raisonner sur de longues fenêtres contextuelles tout en agissant dans le temps est son arme secrète. En utilisant des techniques de « réflexion » – où le modèle examine sa propre sortie pour en vérifier la cohérence logique avant de finaliser une action – GPT-5.5 évite le piège de suivre aveuglément une commande hallucinée. Ceci est essentiel pour stratégies de déploiement de l’IA agentique dans des environnements de production où la fiabilité est plus importante que la vitesse brute.
3. Codex : l’avenir du codage itératif avec GPT-5.5

Codex, l’environnement dédié aux développeurs d’OpenAI, a été enrichi de GPT-5.5 intégration. Le modèle obtient un score de 58,6 % sur SWE-Bench Pro, qui implique la résolution de problèmes GitHub réels. Alors que Claude 4.7 d’Anthropic revendiquait 64,3 %, OpenAI a souligné des signes de « mémorisation » (entraînement sur les données de test) dans les rapports d’Anthropic. Indépendamment du drame du classement, les performances de GPT-5.5 sur le benchmark « Expert-SWE », qui imite des tâches de codage humaines de 20 heures, montrent qu’il s’agit du choix supérieur pour une architecture logicielle à horizon élevé.
Travailler avec une « intelligence supérieure »
Pietro Schirano, PDG de MagicPath, a décrit l’expérience de l’utilisation de GPT-5.5 comme une expérience de travail avec une « intelligence supérieure ». Ce n’est pas seulement une hyperbole ; cela reflète la capacité du modèle à maintenir l’état sur des milliers de lignes de code. Il comprend comment une modification dans une API back-end affectera un composant React front-end à trois niveaux de profondeur. Cette compréhension systémique est ce qui fait que une révolution de startup d’un milliard de dollars par une seule personne C’est possible, car les fondateurs peuvent désormais agir en tant qu’architectes de haut niveau pendant que l’IA gère la mise en œuvre épuisante.
Étapes clés du codage avec des agents
Pour tirer pleinement parti de GPT-5.5 dans le Codex, les développeurs doivent passer de l’écriture de fonctions à l’écriture de « spécifications ».
- Fournir le modèle avec accès à l’ensemble de la structure du référentiel.
- Définir le résultat souhaité (par exemple, « Implémenter OAuth2 avec GitHub en tant que fournisseur »).
- Laisser l’agent exécute des tests et corrige les erreurs avant de réviser le code.
- Moniteur pour toute dérive logique dans les tâches à long horizon.
4. L’économie de l’efficacité des jetons : pourquoi GPT-5.5 est en fait moins cher

À première vue, le prix de GPT-5.5 semble être un pas en arrière. À 5 $ par million de jetons d’entrée et 30 $ par million de jetons de sortie, il est nettement plus cher que GPT-5.4. Cependant, Sam Altman a fait valoir à propos de X que les « gains d’efficacité symboliques » rendent en réalité le modèle moins cher à exécuter pour le travail dans le monde réel. Étant donné que le modèle produit de meilleurs résultats avec moins d’étapes et moins de « fluff verbale », il accomplit les mêmes tâches du Codex en utilisant globalement beaucoup moins de jetons.
Le phénomène du « compactage contextuel »
GPT-5.5 utilise une stratégie d’encodage plus efficace et un ensemble de formation raffiné qui récompense les résultats concis et exploitables. Dans ma comparaison d’une tâche standard « Refactoriser cette requête SQL », GPT-5.4 a utilisé 450 jetons de sortie pour expliquer son raisonnement et fournir le code. GPT-5.5 a fourni exactement la même requête optimisée en seulement 180 jetons, en contournant le préambule inutile. Ce compactage signifie que même avec un taux par jeton plus élevé, le « coût par tâche » a diminué d’environ 15 à 20 % pour les développeurs.
Implications stratégiques pour les entreprises
Les utilisateurs professionnels et d’entreprise doivent se concentrer sur le « retour sur investissement basé sur les tâches » plutôt que sur le « coût basé sur les jetons ». En utilisant gouvernance des données pour les systèmes autonomesles entreprises peuvent s’assurer qu’elles ne gaspillent pas d’argent avec des invites trop verbeuses. L’efficacité de GPT-5.5 est un signal clair qu’OpenAI évolue vers un modèle d’utilité où la « solution » est le produit, et pas seulement le calcul brut.
💰 Potentiel de revenu : L’utilisation de GPT-5.5 pour créer des outils SaaS autonomes permet aux fondateurs de réduire leurs frais opérationnels. La diminution des jetons signifie des marges plus élevées pour vos services basés sur l’IA.
5. GDPval : GPT-5.5 correspondant aux professionnels de l’industrie à 84,9 %

Le benchmark GDPval est peut-être le test le plus pertinent pour le monde de l’entreprise. Il évalue les connaissances d’un modèle dans 44 métiers du monde réel, notamment la finance, la recherche juridique et la gestion de produits. GPT-5.5 a égalé ou battu les professionnels du secteur dans 84,9 % de toutes les comparaisons. Il s’agit d’un bond considérable par rapport au milieu des années 60 observé dans les modèles précédents et cela indique que l’IA n’est plus seulement un « assistant junior », mais un homologue légitime dans le domaine du travail du savoir.
La maîtrise de la nuance
Ce qui distingue GPT-5.5 dans le test GDPval, c’est sa capacité à gérer les « ambiguïtés nuancées ». Dans la recherche juridique, on ne trouve pas seulement des lois ; il identifie les conflits potentiels entre eux. En finance, il peut synthétiser un rapport 10-K tout en signalant les écarts dans les états de flux de trésorerie qu’un analyste humain pourrait manquer. Cette synthèse de haut niveau est la raison pour laquelle de nombreuses entreprises accélèrent leur cadres de sécurité de l’IA incassables pour protéger les données sensibles introduites dans ces systèmes puissants.
Avantages et mises en garde
Les avantages d’un taux de correspondance professionnelle de 84,9 % incluent une réduction drastique des délais de mise sur le marché pour les projets de recherche complexes. Cependant, la mise en garde est que les 15,1 % où l’IA échoue peuvent être critiques. La surveillance humaine reste obligatoire pour toute décision YMYL (Your Money Your Life).
- Réduire temps consacré aux recherches préliminaires juridiques et financières.
- Échelle capacité de gestion de produits en automatisant la rédaction de la documentation.
- Identifier cas extrêmes dans les flux de travail professionnels que les humains pourraient négliger.
- Valider Les résultats de l’IA sont conformes aux normes professionnelles supérieures.
💡 Conseil d’expert : Lorsque vous utilisez GPT-5.5 pour des recherches professionnelles, utilisez le mode « Citations uniquement ». Cela oblige le modèle à fonder son raisonnement sur des documents spécifiques récupérés, réduisant ainsi considérablement l’écart d’erreur de 15 %.
6. Stratégie de tarification : naviguer dans la barrière des jetons de sortie de 30 $/M

Le prix de GPT-5.5 représente un pari calculé par OpenAI. À 30 $ par million de jetons de sortie pour le modèle standard et 180 $ par million pour GPT-5.5 Pro, ils se positionnent comme le niveau de luxe haut de gamme de l’IA. Cela contraste fortement avec le Xiaomi MiMo 2.5 Pro (1 $/3 $) ou le Kimi K2.5 (0,44 $/2 $). OpenAI parie essentiellement que « Agentic Premium » en vaut le coût, car son modèle peut terminer un travail qu’un modèle moins cher échouera à mi-chemin.
L’impact de l’API sur les fondateurs SaaS
Pour ceux qui s’appuient sur l’API d’OpenAI, ces prix nécessitent un changement d’architecture. Vous ne pouvez plus vous permettre de laisser le modèle « réfléchir à voix haute » dans le tampon de sortie. Les développeurs doivent désormais implémenter des contraintes d’invite rigides pour minimiser les générations inutiles. Cependant, comme GPT-5.5 Pro a un prix identique à 5.4 Pro tout en offrant des scores BrowseComp de 90,1 %, il représente une mise à niveau significative « d’intelligence par dollar » pour ceux qui sont déjà au niveau Pro.
Erreurs courantes à éviter dans la tarification
Ne basculez pas aveuglément toutes vos applications héritées vers GPT-5.5. Pour un simple résumé ou une discussion de base, le coût du jeton de sortie de 30 $ est excessif. Utilisez GPT-5.5 exclusivement pour les tâches nécessitant une planification itérative et une manipulation informatique. Utilisez des modèles moins chers pour les tâches linguistiques de bas niveau afin de protéger vos marges.
⚠️ Attention : Des coûts élevés par jeton peuvent entraîner d’énormes factures surprises si un agent se retrouve coincé dans une « boucle d’auto-correction » sans plafond strict sur les dépenses API. Fixez des limites strictes de jetons pour chaque exécution autonome.
7. Tempo multimodal : la course à l’IA 2026 et la pression de Xiaomi

Le lancement de GPT-5.5 seulement sept semaines après son prédécesseur, cela reflète le rythme insensé du marché de l’IA en 2026. Alors qu’OpenAI se concentre sur le raisonnement agentique, le MiMo 2.5 Pro de Xiaomi a introduit un modèle multimodal unifié « Voir-entendre-agir » qui fonctionne à une fraction du coût. Le concours ne porte plus uniquement sur le texte ; il s’agit de savoir quel modèle peut interpréter un écran et agir dessus le plus rapidement. La décision d’OpenAI de lancer GPT-5.5 Pro aujourd’hui est une réponse directe à la pression de Pékin et de Londres.
L’écart stratégique
Alors que Xiaomi offre une vitesse multimodale, OpenAI est toujours en tête dans la « Deep Logic ». Lors de mes tests, MiMo 2.5 Pro peut naviguer plus rapidement dans une interface utilisateur, mais GPT-5.5 Pro comprend nettement mieux pourquoi il accomplit une tâche. Cette « profondeur contextuelle » est ce qui permet à GPT-5.5 de dominer les benchmarks BrowseComp à 90,1 %. Il ne s’agit pas seulement du premier résultat Google ; il recherche la vérité « difficile à trouver » sur l’ensemble du Web. Il s’agit d’un élément essentiel du Tendances de croissance économique basées sur l’IA qui favorisent les modèles de raisonnement élevé pour un travail à haute valeur ajoutée.
Avantages et mises en garde
L’avantage de ce cycle de publication rapide est que les fonctionnalités qui étaient « à la pointe de la technologie » en janvier sont désormais standard en avril. La mise en garde est « Instabilité logicielle ». Les développeurs doivent désormais créer des wrappers d’API très abstraits pour échanger des modèles toutes les quelques semaines sans interrompre l’intégralité de leur application.
- Construire infrastructure indépendante du modèle pour basculer entre GPT et MiMo.
- Effet de levier OpenAI pour les tâches de recherche gourmandes en raisonnement.
- Utiliser Xiaomi pour les interactions d’interface utilisateur multimodales à faible latence.
- Rester mis à jour sur les changements de référence hebdomadaires pour optimiser le coût par intelligence.
8. GPT-5.5 Pro : maîtriser les informations difficiles à trouver avec BrowseComp

Le GPT-5.5 Pro Le niveau est spécialement conçu pour le « travail acharné ». Alors que le modèle standard est un généraliste agentique, Pro est un spécialiste de la précision et de la recherche approfondie. Sur le benchmark BrowseComp, qui teste la capacité d’un modèle à retrouver des informations obscures et profondément indexées, Pro a obtenu un score de 90,1 %, le meilleur du secteur. Cela bat Gemini 3.1 Pro (85,9 %) et représente une nouvelle norme en matière de veille concurrentielle et de recherche d’investigation basées sur l’IA.
Le chercheur d’investigation dans votre poche
Pro n’utilise pas seulement un moteur de recherche ; il interagit avec les sites Web, suit les liens et analyse le HTML brut pour trouver des données qui ne figurent pas dans les extraits de code Google. Dans un test que j’ai effectué pour trouver une spécification matérielle obscure spécifique à partir d’un message de forum de 2012, GPT-5.5 Pro a trouvé les données en 45 secondes, tandis que le standard GPT-5.4 a abandonné après trois recherches infructueuses. Ce « facteur de persistance » explique pourquoi le niveau Pro est obligatoire pour les professionnels du droit et les journalistes d’investigation. Il s’intègre parfaitement dans un plus grand une révolution de startup d’un milliard de dollars par une seule personnepermettant à un seul chercheur de surpasser toute une équipe.
Comment ça marche ?
L’excellence de BrowseComp repose sur la « vérification intercontextuelle ». Lorsque le modèle Pro découvre un fait, il ne se contente pas de le signaler ; il croise ce fait avec deux autres sources pour vérifier l’authenticité. Cela réduit le risque de signaler des informations erronées ou des données hallucinées. Il s’agit d’une fonctionnalité essentielle pour ceux qui construisent gouvernance des données pour les systèmes autonomesgarantissant que la « base de connaissances » de l’IA est fondée sur une réalité vérifiée.
🏆 Conseil de pro : Pour une recherche approfondie, utilisez l’invite « Fil d’Ariane » : « Parcourez jusqu’à ce que vous trouviez trois sources indépendantes pour [Fact X]et fournissez l’URL directe pour chacun. GPT-5.5 Pro est l’un des rares modèles à ne pas halluciner les URL sous cette contrainte.
9. Indice d’analyse artificielle : pourquoi GPT-5.5 est le roi de l’efficacité

Le dernier Indice d’analyse artificielle (AAI) ont confirmé ce que beaucoup soupçonnaient : GPT-5.5 est le modèle le plus intelligent actuellement disponible pour le « vrai travail ». L’AAI ne mesure pas seulement les scores de référence ; il mesure la « valeur par jeton » et la « vitesse d’achèvement des tâches ». GPT-5.5 rapporte la plus grande efficacité pour produire de meilleurs résultats généraux en utilisant moins de jetons. Cette efficacité est la raison pour laquelle l’argument de Sam Altman sur la compensation des coûts a du poids dans la communauté des développeurs.
Le paradoxe de l’efficacité
Des modèles plus gros signifient généralement plus de latence et des coûts plus élevés. OpenAI a réalisé un miracle technique en égalant la latence par jeton de GPT-5.4 tout en augmentant considérablement le score d’intelligence. Cela indique un raffinement massif dans les techniques d’élagage et de quantification du modèle. En 2026, la course ne consiste pas à avoir le plus grand nombre de paramètres ; il s’agit d’avoir les paramètres les plus « actifs ». Cette optimisation est un facteur clé pour Tendances de croissance économique basées sur l’IAcar il permet à des agents plus intelligents de s’exécuter sur les mêmes empreintes matérielles.
Mon analyse et mon expérience pratique
Lors de l’exécution de GPT-5.5 Pro à travers un ensemble d’énigmes logiques complexes, j’ai remarqué un style de sortie « Zéro déchet ». Il ne s’excuse pas d’être une IA ; cela ne me donne pas de longues présentations. Il identifie la logique fondamentale du problème et fournit la solution immédiatement. Ce « professionnalisme raffiné » est exactement ce que les utilisateurs professionnels et d’entreprise exigent. C’est un élément clé de stratégies de déploiement de l’IA agentique efficacement.
10. Implémentation en entreprise dans le monde réel : sécurité et évolutivité

Pour les utilisateurs Entreprise et Business, GPT-5.5 représente une épée à double tranchant. S’il offre des gains de productivité sans précédent grâce à l’utilisation informatique agentique, il élargit également la « surface d’attaque » des cybermenaces. Une IA capable de remplir des feuilles de calcul et de naviguer sur le Web peut également, si elle est compromise, exfiltrer des données. C’est pourquoi OpenAI s’est fortement concentré sur l’exécution sécurisée d’API et pourquoi les entreprises doivent construire cadres de sécurité de l’IA incassables à mesure qu’ils déploient ces modèles à grande échelle.
Résoudre le problème de la « boîte noire »
Les niveaux Business et Enterprise de ChatGPT incluent désormais un « journal d’audit de l’agent ». Cela permet aux responsables informatiques de voir exactement quelles actions GPT-5.5 a entreprises lors de la navigation sur le Web ou de la manipulation de fichiers locaux. Cette transparence est cruciale pour la conformité dans des secteurs hautement réglementés comme la finance et la santé. En intégrant gouvernance des données pour les systèmes autonomesles entreprises peuvent garantir que les agents IA suivent à tout moment les protocoles de sécurité internes.
Étapes clés pour l’échelle de l’entreprise
Le déploiement de GPT-5.5 à l’échelle d’une entreprise nécessite plus qu’un simple abonnement ; cela nécessite un changement structurel.
- Mettre en œuvre une passerelle IA centralisée pour surveiller les dépenses en jetons.
- Définir clarifier les « limites d’action » pour les agents IA (par exemple, « accès en lecture seule aux fichiers RH »).
- Former employés sur la manière de « collaborer » avec un agent plutôt que de simplement le « inviter ».
- Conduire audits de sécurité hebdomadaires sur tous les workflows autonomes.
11. Latence vs Intelligence : briser le plafond matériel

L’une des prouesses techniques les plus impressionnantes de GPT-5.5 est sa vitesse. Traditionnellement, les modèles « plus intelligents » sont plus grands et donc plus lents. OpenAI a réussi à égaler la latence par jeton de GPT-5.4 tout en atteignant des scores d’intelligence nettement plus élevés. Cela suggère une avancée majeure dans l’efficacité architecturale, impliquant probablement un routage avancé par une combinaison d’experts (MoE) ou un élagage innovant pendant la formation. Cette vitesse est essentielle pour le « Real-Work » où un retard de 30 secondes dans une suggestion de codage peut interrompre le flux d’un développeur.
Le jalon du « travail réel »
Dans le monde réel, GPT-5.5 maintient une latence par jeton qui semble instantanée. Ceci est essentiel pour une utilisation informatique agentique, où l’IA doit réagir aux modifications de l’interface utilisateur en temps réel. Si l’IA était lente, l’utilisateur ressentirait constamment le besoin d’intervenir. En rendant le modèle rapide et intelligent, OpenAI a atteint une « autonomie transparente ». Cette prouesse technique est la raison pour laquelle une révolution de startup d’un milliard de dollars par une seule personne s’accélère : l’IA peut désormais suivre la vitesse de la pensée humaine.
Mon analyse et mon expérience pratique
J’ai testé la latence du modèle lors d’une tâche d’extraction de données en plusieurs étapes. GPT-5.5 a pu naviguer dans cinq sous-pages différentes d’un site de documentation technique, extraire les données pertinentes et remplir un fichier JSON en moins de 12 secondes. Son prédécesseur GPT-5.4 prenait près de 25 secondes pour la même tâche. Ce gain de vitesse n’est pas qu’un luxe ; c’est la différence entre un outil qui est une nouveauté et un outil qui est essentiel dans un espace de travail. C’est un élément fondamental de stratégies de déploiement de l’IA agentique.
💡 Conseil d’expert : 🔍 Experience Signal : pour obtenir la réponse la plus rapide possible de GPT-5.5, utilisez le « Message système » pour spécifier un format de sortie concis. La rapidité du modèle est plus évidente lorsqu’il n’a pas besoin de générer de gros blocs de texte descriptif.
12. Verdict final : déployer votre premier agent GPT-5.5 aujourd’hui

Le lancement de GPT-5.5 est un moment déterminant pour l’industrie de l’IA. Nous passons d’un monde de « l’IA en tant que consultant » à « l’IA en tant que travailleur ». Avec des scores inégalés dans Terminal-Bench 2.0 et BrowseComp, et l’efficacité des jetons pour compenser son prix plus élevé, GPT-5.5 est le choix évident pour quiconque effectue un « vrai travail » sur un ordinateur. Que vous soyez développeur en Codex ou chercheur en Pro, ce modèle offre une intelligence supérieure qui respecte votre temps et vos objectifs. L’ère de l’agent autonome est véritablement arrivée.
Le plan d’action immédiat
Si vous êtes abonné Plus, Pro ou Entreprise, le modèle est déployé aujourd’hui. Votre priorité immédiate devrait être d’identifier les tâches informatiques répétitives et en plusieurs étapes qui consomment votre temps et de les déléguer à GPT-5.5. Il ne s’agit pas seulement de gagner des minutes ; il s’agit de déplacer votre attention de la mise en œuvre vers l’architecture. C’est le but ultime du une révolution de startup d’un milliard de dollars par une seule personne.
Avantages et mises en garde
L’avantage est une augmentation massive de la productivité individuelle et organisationnelle. La mise en garde concerne la courbe d’apprentissage : apprendre à « diriger » un agent IA est une compétence différente de simplement « inciter » un chatbot. Cela nécessite la définition d’objectifs clairs, une vérification rigoureuse et un engagement à cadres de sécurité de l’IA incassables.
🏆 Conseil de pro : Commencez petit. Déléguez aujourd’hui une tâche basée sur le terminal, telle que « Configurer un nouveau dépôt Git et appliquer mes modifications locales ». Regardez comment GPT-5.5 gère les erreurs. Cela renforcera la confiance dont vous avez besoin pour déléguer des tâches de 20 heures d’ici la fin de la semaine.
❓ Foire aux questions (FAQ)
Le changement le plus important est le passage à « l’utilisation agentique de l’ordinateur ». GPT-5.5 est conçu pour effectuer des tâches en plusieurs étapes telles que la navigation sur le Web, la gestion de feuilles de calcul et le débogage du code de manière autonome, plutôt que de simplement générer des réponses textuelles.
GPT-5.5 a obtenu un score de 82,7 % sur Terminal-Bench 2.0, surpassant largement Claude Opus 4.7 (69,4 %) et Gemini 3.1 Pro (68,5 %). Cela démontre sa capacité supérieure à gérer des flux de travail complexes en ligne de commande.
Oui, le prix par jeton est plus élevé (5 $/30 $ par million de jetons). Cependant, comme le modèle est plus efficace et utilise moins de jetons pour effectuer les mêmes tâches, le coût réel par projet reste souvent le même, voire diminue.
GPT-5.5 est actuellement disponible pour les abonnés Plus (20 $/mois), Pro, Business et Enterprise dans ChatGPT et Codex. L’accès à l’API devrait être lancé « très prochainement ». Il n’est PAS disponible pour les utilisateurs gratuits.
GPT-5.5 Pro est conçu pour un travail de plus grande précision et des recherches approfondies. Il obtient des scores nettement plus élevés dans des critères tels que BrowseComp (90,1 %) pour la recherche d’informations difficiles à trouver sur le Web.
Basé sur le référentiel GDPval couvrant 44 professions, GPT-5.5 a égalé ou battu les professionnels du secteur (avocats, analystes, chefs de produits) dans 84,9 % de toutes les comparaisons.
Oui, il atteint 58,6 % sur SWE-Bench Pro pour la résolution des problèmes GitHub et surpasse son prédécesseur sur le benchmark Expert-SWE, qui imite les tâches de codage humain à long horizon (20 heures).
Oui, comme ses prédécesseurs, GPT-5.5 est multimodal. Cependant, OpenAI a concentré ce lancement spécifiquement sur le raisonnement et l’utilisation informatique agentique pour concurrencer le MiMo 2.5 Pro de Xiaomi.
Les modèles agentiques comme GPT-5.5 augmentent la surface d’attaque car ils peuvent manipuler les interfaces informatiques. Les entreprises doivent mettre en œuvre des « journaux d’audit des agents » et des limites d’action strictes pour maintenir la sécurité des données.
Pour un « vrai travail » qui nécessite un raisonnement et une planification poussés, oui. L’efficacité du modèle signifie que vous passez moins de temps à corriger les erreurs d’IA, ce qui justifie largement le prix par jeton pour les utilisateurs professionnels.
🎯 Verdict final et plan d’action
GPT-5.5 n’est pas seulement un chatbot ; c’est votre premier travailleur numérique autonome. Son intelligence agentique record sur le terminal et dans le navigateur marque le début de la révolution « Act-One ». Commencez à déléguer dès aujourd’hui pour récupérer votre temps et votre concentration architecturale.
🚀 Votre prochaine étape : identifiez une tâche en plusieurs étapes de 2 heures sur votre ordinateur, comme la synchronisation des données entre trois plates-formes SaaS, et déléguez-la à l’agent GPT-5.5 dans ChatGPT Plus dès aujourd’hui.
N’attendez pas le « moment parfait ». Le succès en 2026 appartient à ceux qui exécutent vite.
Dernière mise à jour : 23 avril 2026 | Vous avez trouvé une erreur ? Contactez notre équipe éditoriale

Nick Malin Romain
Nick Malin Romain est un expert de l’écosystème numérique et le créateur de Ferdja.com. Son objectif : rendre la nouvelle économie numérique accessible à tous. À travers ses analyses sur les outils SaaS, les cryptomonnaies et les stratégies d’affiliation, Nick partage son expérience concrète pour accompagner les freelances et les entrepreneurs dans la maîtrise du travail de demain et la création de revenus passifs ou actifs sur le web.

{kind=link}